
How is your microservice architecture doing?
It all started when my new boss stepped into my door and asked me if I had a clue how our system was working. In an ideal world we would have teams and developers who work on a isolated context with clear boundaries. They develop, test, deploy, monitor and operate everything by themselves. They are on 24/7 call and therefore they do everything possible that nothing fails. The system is stable and brings in the money.
In my world however, things are a little different.
Being there for over 2 years and a developer I knew from history vaguely what was going on, who did what and even sometimes why. But it struck me that we had no clear overview. My boss wanted to know what he is dealing with and could only find (outdated) wiki pages and knowledge of some people. Wikis are great (Where Information Kills Itself) but developers tend to not updated them. People come and leave or forget things if they not constantly working on it. The only person knowing what is going on is the developer (and through incidents operations). The former person does not like to leave his development environment and documenting stuff is mostly boring. The truth is in the source. I’m guilty of that as well.
To make things worse we were (and are) in a transition from a monolithic application (but distributed over a dozen services) to a much more ‘microservice’ landscape. So new services were popping up left and right, teams were slicing the old ones and creating many much smaller ones. We have now more than 70 different services composing our platform.
How do you know what’s going on?
I ended up in a role taking care of the whole platform and I was wondering do I really need to know? I can’t possible understand the whole system. We do have a team architect in every team. We have created a set of rules how we develop services: ‘API backwards compatible, REST, HATEOAS, phoenix’ style. The team knows it the best when and how to create new services and how to deal with them. They know the business logic.
The rule set took a while to sink in to peoples minds (we talk about months > 18) but finally it started to show. In case you are wondering, we do have a couple of more rules then the ones I just stated ;-). Still the teams were working mostly by themselves and it turns out to be okish.
After a couple of month I had the gut feeling that I know nothing about the platform and that this is not so good. Not even about programming languages used. We have our rules but one guy managed to sneak in Scala anyway. Not a bad choice but those things have a broader impact on the organisation.
As we hired more and more people (internal & consultants) and with over 70 services it is hard to understand the system. Especially when you grew from a distributed monolith and still (of course) have the roots of that in the system. So that is a problem. Another thing we ran into is that sometimes you need to make breaking API changes. In this case it is useful to know who is your client to get that code changed as well. Maybe strict CDC tests would also reveal that. So an overview of all software to get started/get more information as well as the overall picture is sometimes needed.
Our own tool.
So about a year ago we decided to change that and wrote a tool to collect information about every single software we wrote. The developers were demanding it. We could not find any documentation software out there which deals with different repos, different languages, information aggregation in the way we thought we need it. About the same time we went through our regular licenses check to make sure we do not use any licenses which we are not allowed to (read AGPL and friends). Being JVM based and using Maven and SBT mostly I could gather all the information I needed but it was very tedious and took a couple of days. So we decided to include that in the collection of information as well. The idea is simple: many build tools generate license (and therefore dependency) information. We simply parse those files. We have implementations for gradle, maven, sbt and some javascript build tools. For the few others we use static configs (which needs manually updates). It has the nice effect of always knowing which version of what we use at the moment and if a library as some security problems we can identify which sources needs to be updated.
We always want to know of every piece of our software:
- The name
- Which team is responsible
- Description what it does
- What kind is it? Library/Tool/Service
- Where is the wiki page with more information
- Where is the build chain
- All license/dependency information
- VCS root
So every team put a yaml file in the source root of the software and modified the CI template to run our tool to gather/generate all the information and upload them to the wiki. Every time a developer now checks in something we update the information. It took some weeks to get the teams to introduce this file but finally we are done.
But there is more to it …
Seeing this information for some time I realized how much more we could do, e.g. if you run on virtual machines and secure them with iptables. If you introduce a new connection from one service to another, and depending on network zones and hardware firewalls, it will trigger a (half) manual action by operations. If I would know the connections and dependencies between the services we could generate it automatically, I could draw the whole architecture. I drew a picture of our bounded contexts some time ago by hand and I keep it updated but what if I can put a mapping between services and contexts in the described yaml file? So again I set out to see if I can find a piece of software which does it for me. We wrote our own tool for the first use case but I was wondering if somebody else came up with something interesting in the mean time.
I found many monitoring and documentation tools which run in production and capture the connections there. I think this is very useful and we may need something like this as well to see how the current situation is. But I could not find tools which generate how the situation should be (plus all the other information we wanted to know about the software). Phil Calcado of (Ex)Soundcloud pointed me to some slides where you see something similar and during GOTO Berlin one guy from Spotify talked about their ‘System-Z’ which does something like we wanted. But nothing of that was/is available as Open Source.
Let’s do it.
So, here we go again.
The last couple of days my colleague Felix and I started to enhance our current code.
First I thought about what we might need (and maybe not just us) and what we could easily gather automatically or the teams would have to contribute. Here is the first try:
# ID Generated by server
# - Mandatory
ID: w0er7wq30sodacdhofk
# Name of the Service
# - Mandatory
Name: UberBillPrint
# One of (Service|Tool|Mobile|Lib), really can be anything in the database, depends
# on the user
# - Mandatory
Type: Service
# Servicename, with that name, other will find and connect to me in their 'talks_to' section
# - Mandatory in case of Service
Servicename: UBP
# Which team is responsible for this software
# - Mandatory
Team: Team Blue
# What do I do ?
# - Mandatory
Description: Provides an awesome REST Service with Billing and Printing (including ordering an Uber Taxi).
# Maybe just for Mobile|Service: where do I run, am I already in production?
# - Value can be anything, what fits for you is right.
# - Mandatory in case of service|mobile
Status: (production|dev|test|prototype)
# Where is my source code
# - Value can be anything, maybe if URL starts with http we link it later
# - Mandatory
VCS: git://vcs.local/billprint
# Links to several resources which a user can click on
Links:
# - Values need to be 'linked text' : 'url'
homepage: http://wiki.local/billprint
buildchain: http://ci.local/billprint
monitoring: http://monitoring.local/billprint
# Only applicable to services.
# This software is providing the following named service, on these ports.
# If there is just one provided service you can leave out the 'default' section.
# If you have more than one (why?)
# you need to specify the default port. DNS for cheap.
# - Values can be Name:Port:default connection
# - Mandatory in case of service
provides:
- UberBillPrint:8443:default
- Bootstrap:8600
# I need to talk to these service, this can be:
# - <Servicename>
# - <Servicename>:<NamedPort>
# - <Servicename>:<Port>
# - <IP>:<Port>
# Preferred is Servicename with or without NamedPort. All others are just fallbacks,
# for things you might not have under your control or located outside.
# - Mandatory in case of service
talks_to:
- BIL
- PRN:Print
- UBR:3000
- 192.168.178.2:100
# In which network zone am I located. This can be interesting for hardware firewalls.
# - Values can be anything, what fits for you is right.
# - Optional
Network_zone:
BACKEND
# This should not happen, but reality is: You have deployment dependencies
# which you can't fix in the near future. So we want to declare the Service names you need.
# - Values can be any other Servicename.
# - Optional
Needs_to_be_deployed_before:
USR
# I belong to the following context. This is used to get a better overview.
# - Values can be anything, what fits for you is right.
# - Optional
Belongs_to_Bounded_Context:
Delivery
# Defining how the machine/container should look like (virtual) hardware wise.
# - Values can be anything, what fits for you is right.
# - Optional
runtime:
cpu: L
ram: S
disk: XL
As I came up with my fictional example and trying to figure out what information we would require to have I thought this whole thing is totally customisable by the user. Almost all parameters are optional. The tool should work like this:
- A client runs in the source directory of the software and can gather (or not) additional information. It might transform a yaml file (like we choose to do) into json, enrich it with generated license and vcs information and upload it to a server. This client could also be just a curl command and just reading in a file in json format.
- The server indexes it and provides an api to access the data.
- Other clients query the server and generate firewall rules, docker-compose files, visualizes the architecture, list all services and their description and so on.
- The format needs to be flexible and I do not want to force anybody to use things which might not be interesting for them. So we settled for now as mandatory attributes: ID, Name, Type, Team, Description, VCS. This is the minimal information we need. I guess we need to discuss the VCS when we want to model our whole architecture which includes a commercial database.
- The server accepts everything in json which has the mandatory fields. Your client needs to make sense of it. We want to provide a recommended set of data structure and some clients which do something useful with it.
Current work.
This is work in progress and we coded a few hours on a prototype to see if this is doable. We see this tool to serve multiple goals:
- Document your microservices
- Visualize your Architecture
- Generate data for your infrastructure (firewall, docker-compose, etc)
- Find used libraries (with security problems)
We already made some progress and even got some cool visualization. D3 is cool if you know how to use it (or just stackoverflow it).
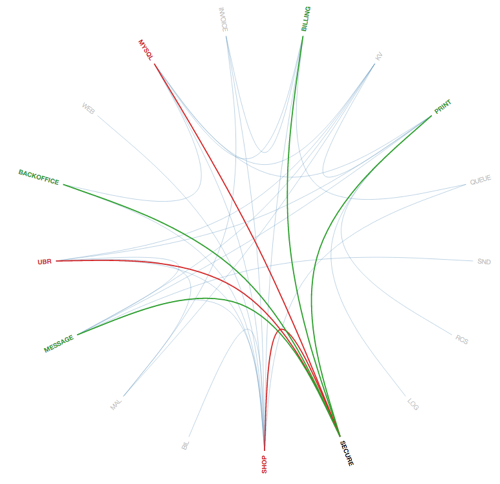
We have tons of ideas what might be possible with that. But first things first.
Thanks for your time and for reading so far. I would love to know :
- What do you think of all this?
- How do you handle the above questions?
- Which tools do you use?
- What other use case do you have?
- Would be something like this interesting to you? I love coding but I’m happy to use a better tool if you know one.
- Would that be interesting if we open source it ?
Any thoughts ?
Oliver